












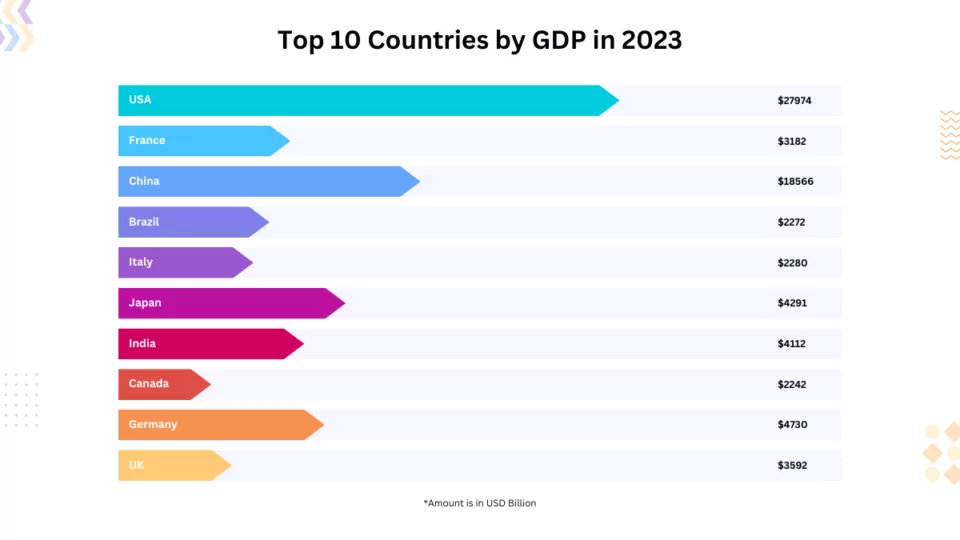



































Introduction
Whether you’re a seasoned car enthusiast or just dipping your toes into the world of automobiles, navigating the vast array of car models can be overwhelming. From performance to design, each aspect plays a crucial role in determining the best of the best. In this guide, we’ll take a d[……]
