












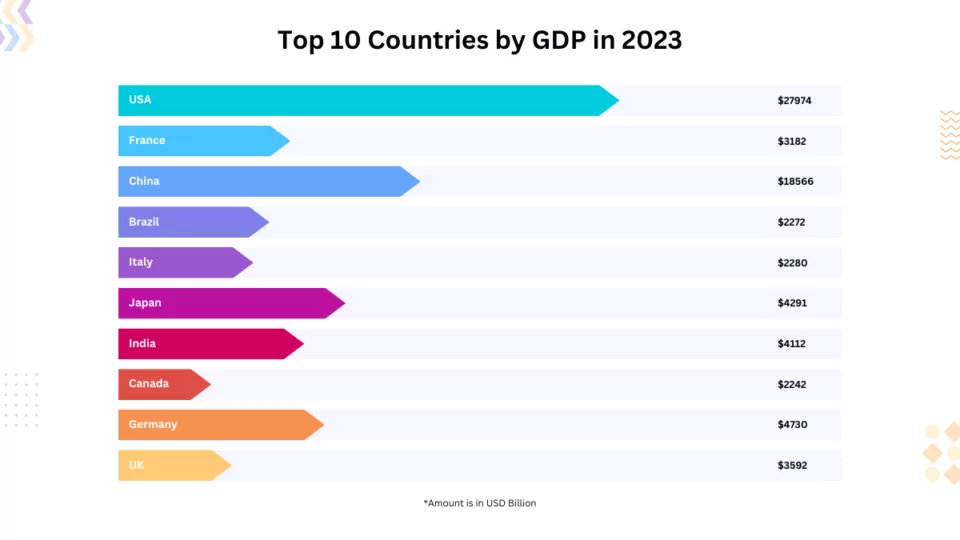

































Introduction
Are you on the hunt for the best car under 5 lakh? Look no further! In this comprehensive guide, we’ll explore the top contenders in the budget-friendly car market, helping you make an informed decision that aligns with your needs and preferences.
In today’s fast-paced world, owning a[……]
